
The following encapsulates commonly used terms throughout tinymorph. By all means it includes
both technical and non-technical definitions that should help with knowing about the system.
inlay hints
Special markers that appear in your editor to provide additional context about context of the code1
In a context of a text editor, inlay hints can work as a suggestion from a providers based on current context.
auto-regressive model
A statistical model is autoregressive if it predicts future values based on past values. For example, an autoregressive model might seek to predict a stock’s future prices based on its past performance.
In context of LLMs, generative pre-trained transformers (GPTs) are derivations of auto-regressive models where it takes an input sequence of tokens length and predicting the next token at index .
Auto-regressive models are often considered a more correct terminology when describing text-generation models.
transformers
A multi-layer perception (MLP) architecture built on top of a multi-head attention mechanism (Vaswani et al., 2023) to signal high entropy tokens to be amplified and less important tokens to be diminished.
low-rank adapters
Paper: “LoRA: Low-Rank Adaptation of Large Language Models” (Hu et al., 2021), GitHub
ELI5: Imagine you have a big complex toy robot. Now you want to teach this robot some new tricks. With LoRA, you are giving this robot a small backpack. This backpack won’t change how the robot function, but will give it some new cool tricks. Now with SAEs, you are adding enhancement directly into the robot, which makes it a lot better at some certain tricks.
The idea is to freeze a majority of the network weights, and inject trainable rank decomposition matrices to influence the models’ outputs.
each LoRA layer can then be merged with the main models, in which create specialised models on given tasks. The main benefit of LoRA is to reduce costs for fine-tuning tasks.
In a sense, LoRA is a different comparing sparse autoencoders
- For LoRA, we are controlling the outputs of a models by training additional “parameters” to add into the models
- With SAEs, we are directly editing features activations within the neural net, which means we don’t have to worry about fine-tuning the model. We observe this through Claude’s Golden Gate Bridge.
mechanistic interpretability
alias: mech interp
The subfield of alignment that delves into reverse engineering of a neural network.
To attack the curse of dimensionality, the question remains: How do we hope to understand a function over such a large space, without an exponential amount of time?
manual steering
also known as features steering
refers to the process of manually modifying certain activations and hidden state of the neural net to influence its outputs
For example, the following is a toy example of how GPT2 generate text given the prompt “The weather in California is”
flowchart LR
A[The weather in California is] --> B[H0] --> D[H1] --> E[H2] --> C[... hot]
To steer to model, we modify layers with certain features amplifier with scale 20 (called it )2
flowchart LR
A[The weather in California is] --> B[H0] --> D[H1] --> E[H3] --> C[... cold]
One usually use techniques such as sparse autoencoders to decompose model activations into a set of interpretable features.
For feature ablation, we observe that manipulation of features activation can be strengthened or weakened to directly influence the model’s outputs
superposition hypothesis
Linear representation of neurons can represent more features than dimensions. As sparsity increases, model use superposition to represent more features than dimensions.
When features are sparsed, superposition allows compression beyond what linear model can do, at a cost of interference that requires non-linear filtering.
features
When we talk about features (Elhage et al., 2022, p. see “Empirical Phenomena”), the theory building around several observed empirical phenomena:
- Word Embeddings: have direction which coresponding to semantic properties (Mikolov et al., 2013). For
example:
V(king) - V(man) = V(monarch) - Latent space: similar vector arithmetics and interpretable directions have also been found in generative adversarial network.
We can define features as properties of inputs which a sufficiently large neural network will reliably dedicate a neuron to represent (Elhage et al., 2022, p. see “Features as Direction”)
hyperparameter tuning
Refers to the process of optimizing the hyperparameters of a model to improve its performance on a given task.
In the context of mech interp, we refer to adjusting given scale and entropy of given feature vectors.
ablation
In machine learning, ablation refers to the process of removing a subset of a model’s parameters to evaluate its predictions outcome.
Often also referred as feature pruning, but they have some slightly different meaning.
residual stream
flowchart LR
A[Token] --> B[Embeddings] --> C[x0]
C[x0] --> E[H] --> D[x1]
C[x0] --> D
D --> F[MLP] --> G[x2]
D --> G[x2]
G --> I[...] --> J[unembed] --> X[logits]
residual stream has dimension where
- : the number of tokens in context windows and
- : embedding dimension.
attention mechanism process given residual stream as the result is added back to :
logits
the logit function is the quantile function associated with the standard logistic distribution
inference
Refers to the process of running the model based on real world inputs to generate text completions.
next-token prediction is commonly used in the context of LLMs.
time-to-first-tokens
Denotes the latency between request arrivate and the first output token generated by system for the request.
minimise TTFT will help with UX for users.
sparse autoencoders
abbrev: SAE
Often contains one layers of MLP with few linear ReLU that is trained on a subset of datasets the main LLMs is trained on.
see also: landspace, more technical details
empirical example: if we wish to interpret all features related to the author Camus, we might want to train an SAEs based on all given text of Camus to interpret “similar” features from Llama-3.1
definition
We wish to decompose a models’ activitation into sparse, linear combination of feature directions:
Thus, the baseline architecture of SAEs is a linear autoencoder with L1 penalty on the activations:
training it to reconstruct a large dataset of model activations , constraining hidden representation to be sparse
L1 norm with coefficient to construct loss during training:
intuition
We need to reconstruction fidelity at a given sparsity level, as measured by L0 via a mixture of reconstruction fidelity and L1 regularization.
We can reduce sparsity loss term without affecting reconstruction by scaling up norm of decoder weights, or constraining norms of columns durin training
Ideas: output of decoder has two roles
- detects what features acre active ⇐ L1 is crucial to ensure sparsity in decomposition
- estimates magnitudes of active features ⇐ L1 is unwanted bias
Gated SAE
see also: paper
uses Pareto improvement over training to reduce L1 penalty (Rajamanoharan et al., 2024)
Clear consequence of the bias during training is shrinkage (Sharkey, 2024) 3
Idea is to use Gated ReLU encoder [@shazeer2020gluvariantsimprovetransformer; @dauphin2017languagemodelinggatedconvolutional]:
where is the (pointwise) Heaviside step function and denotes elementwise multiplication.
| term | annotations |
|---|---|
| which features are deemed to be active | |
| feature activation magnitudes (for features that have been deemed to be active) | |
| sub-layer’s pre-activations |
to negate the increases in parameters, use weight sharing:
Scale in terms of with a vector-valued rescaling parameter :
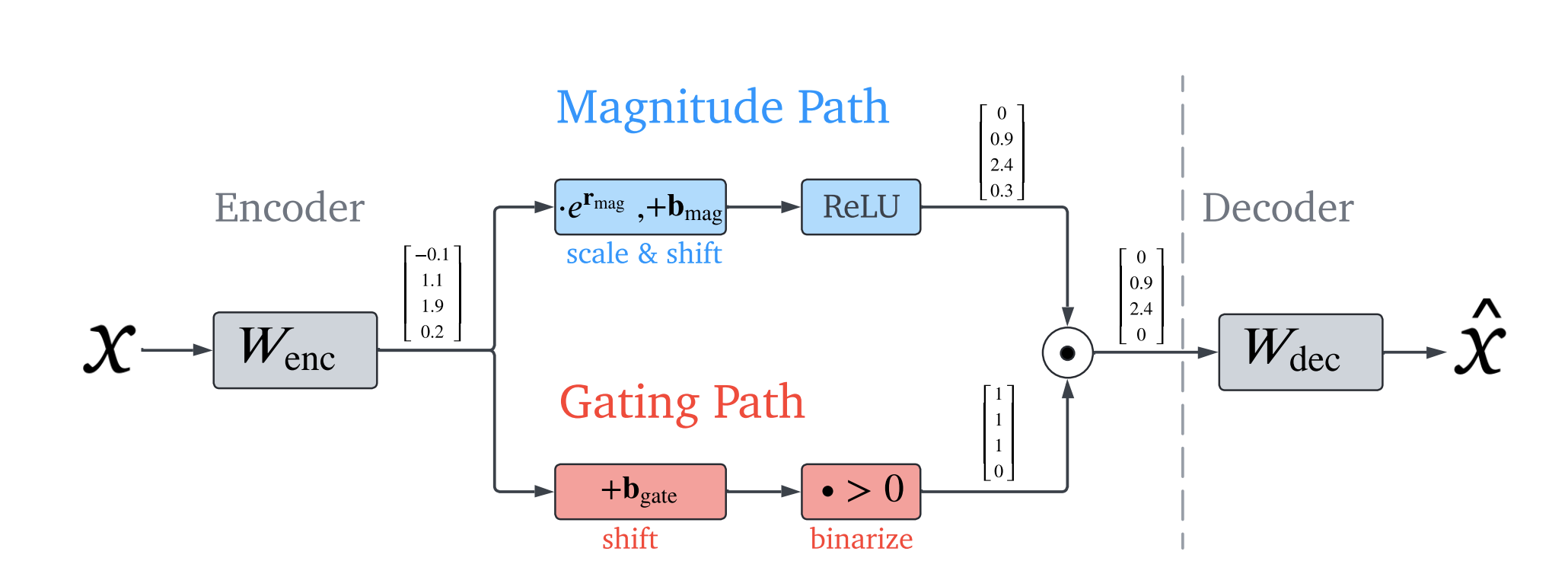
figure 3: Gated SAE with weight sharing between gating and magnitude paths
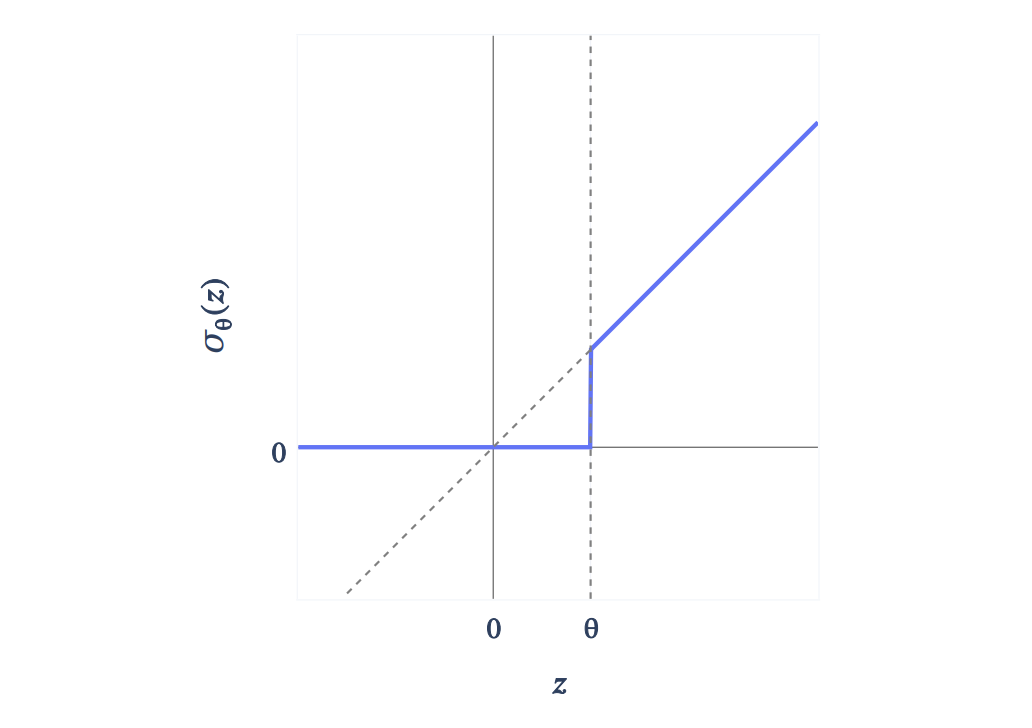
figure 4: A gated encoder become a single layer linear encoder with Jump ReLU (Erichson et al., 2019) activation function
feature suppression
See also link
Loss function of SAEs combines a MSE reconstruction loss with sparsity term:
the reconstruction is not perfect, given that only one is reconstruction. For smaller value of , features will be suppressed
retrieval augmented generation
First introduced by (Lewis et al., 2021) which introduces a pipeline that includes a retriever models queried from existing knowledge base to improve correctness and reduce hallucinations in LLM generations.
How would this work with SAEs specifically?
- Run an embedding models ⇒ SAEs to interpret features from relevant documents. ⇒ Search related features.
- Added said documents embedded in input tensors ⇒ better planning for contextual embeddings.
See also Contextual Document Embeddings
hallucinations
A phenomenon where contents generated by LLMs are misleading and inconsistent with real-world facts or users inputs. This poses a threat to the safety of the system, as it can lead to misinformation and harmful outcomes (Huang et al., 2023)
KV cache block
While generating tokens in auto-regressive models, previously generated tokens are fed into the network again while generating a new tokens. As input sequence becomes longer, inference FLOPs will grow exponentially.
KV cache solves this problem by storing hidden representations or previously computed key-value pairs while generating a new tokens.
the KV-cache will then be prefilled during forward propagation.
See also source
FLOPs
Also known as floating point operations. Used as a common metric to measure the the computer performance.
agency
The ability and freedom for an individual to act based on their immediate context and interests.
Ivan Illich (Illich, 1973) claimed that through proper use of technology, one can reclaim agency and practical knowledge for your everyday Joe.
Tools for conviviality (conviviality means ‘alive with’) suppress other ideas and systems of knowledge and concentrate control of knowledge and power in the few and the elite […] - Tools for Conviviality
The idea of agency for machine learning is that models have the ability to enact on their own without human intervention. Given the emergent properties of “intelligence” in these systems, it is crucial for us to understand their world view such that we can make informed decisions for building interfaces that will amplify our own cognitive abilities.
See also Alex Obenauer’s work on personal computing, Self-Determination Theory
data
Representation of information in a formalised manner suitable for communication, interpretation, or processing by humans or by automatic means.
connectionism
Initially conceptualized to represent neural circuitry through mathematical approach. (Rosenblatt, 1958)
Second wave blossomed in late 1980s, followed by Parallel Distributed Processing group (Rumelhart et al., 1986), where it introduced intermediate processors within the network (often known as “hidden layers”) alongside with inputs and outputs. Notable figures include John Hopfield, Terence Horgan.
Third waves (the current meta we are in) are marked by the rise in deep learning, notable contributions include the rise to fame of large language models. This era focuses artifical neural networks, focusing on designing efficient architecture to utilize available computes.
bias bug
The primary methods on fighting against bias bugs in contemporary AI system includes increase in data diversity.
There is a timeless saying in computer science “Garbage in Garbage out”, which essentially states that bad data will produce outputs that’s of equal quality. This is most prevalent in AI, given the existence of these networks within a black-box model. One case of this is the very first iterations of Google Photos’ image recognition where it identified people with darker skins as “gorillas” (BBC News, 2015).
Truth is, data lacks context. A prime example of this US’ COMPAS used by US courts to assess the likelihood of criminal to reoffend. ProPublica concluded that COMPAS was inherently biased towards those of African descent, citing that it overestimated the false positives rate for those of African descent by two folds (Angwin et al., 2016). Interestingly, a study done at Darthmouth showed a surprising accuracy on the rate of recidivism with random volunteers when given the same information as the COMPAS algorithm (Dressel, 2018). The question remains, how do we solve fairness and ensure DEI for marginalized groups when there is obviously prejudice and subjectivity that introduce bias at play? It is not a problem we can’t solve, rather collectively we should define what makes an algorithm fair.
Footnotes
-
Introduction from JetBrains, but this is implemented widely in other IDEs as well (VSCode, Neovim, Emacs, etc.) ↩
-
This is a toy representation of hidden layers in MLP, in practice, these models contain ~ 96 layers of MLP or more. ↩
-
If we hold fixed, thus L1 pushes , while reconstruction loss pushes high enough to produce accurate reconstruction.
An optimal value is somewhere between. However, rescaling the shrink feature activations is not necessarily enough to overcome bias induced by L1: a SAE might learnt sub-optimal encoder and decoder directions that is not improved by the fixed. ↩